- 戳上方蓝字“牛皮糖不吹牛”关注我
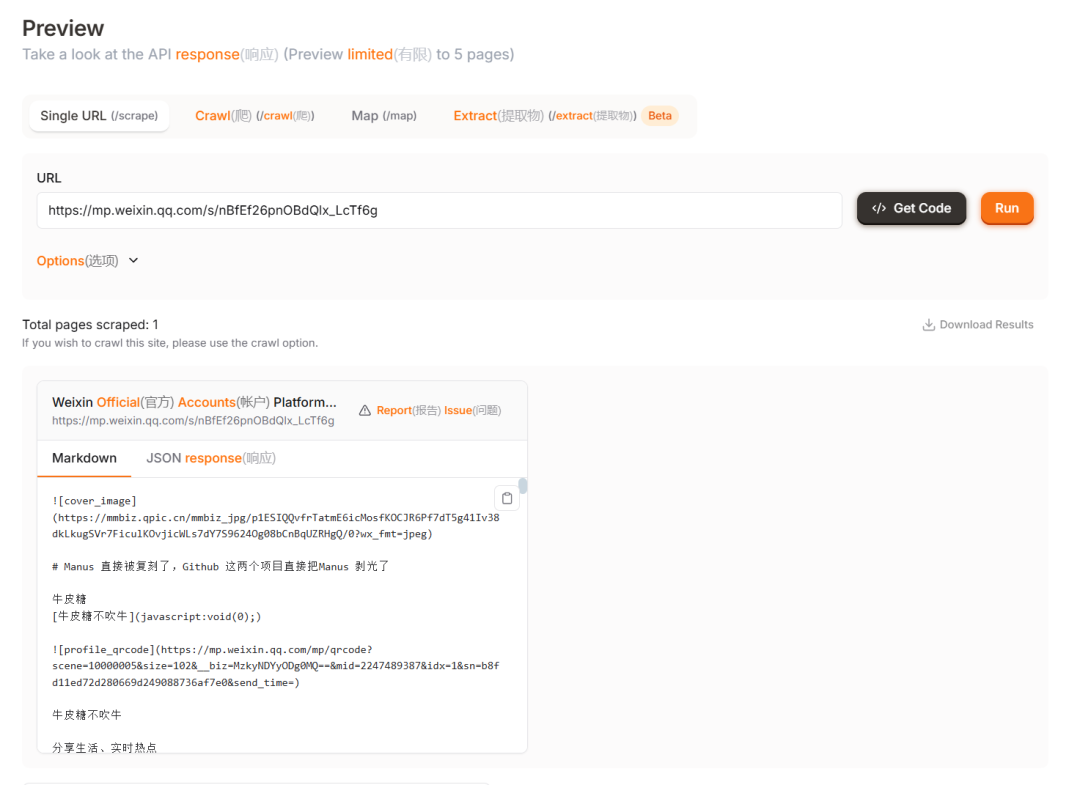
大家好,我是牛皮糖Firecrawl 是一款强大的API服务,能够将整个网站转化为适合大型语言模型(LLM)的Markdown格式或结构化数据。它具备先进的抓取、爬取和数据提取能力,无需站点地图即可处理所有可访问的子页面。
主要功能
抓取(Scrape)
• 功能:抓取单个URL的内容,并以LLM就绪的格式返回,包括Markdown、结构化数据、截图、HTML等。
• 使用示例:`from firecrawl.firecrawl import FirecrawlApp
app = FirecrawlApp(api_key=”fc-YOUR_API_KEY”)
scrape_status = app.scrape_url(
‘https://firecrawl.dev‘,
params={‘formats’: [‘markdown’, ‘html’]}
)
print(scrape_status)`
爬取(Crawl)
• 功能:爬取一个URL及其所有可访问的子页面,并返回每个页面的内容。
• 使用示例:```
crawl_status = app.crawl_url( 'https://firecrawl.dev', params={ 'limit': 100, 'scrapeOptions': {'formats': ['markdown', 'html']} }, poll_interval=30 ) print(crawl_status)
1 |
|
提取(Extract)
• 功能:从单个页面、多个页面或整个网站中提取结构化数据,支持基于提示词或模式。
• 使用示例:```
extract_response = app.extract( urls=["https://firecrawl.dev/*", "https://docs.firecrawl.dev/"], prompt="Extract the company mission from the page.", schema={ "type": "object", "properties": { "company_mission": {"type": "string"} }, "required": ["company_mission"] } ) print(extract_response)
## 技术特点
- • **多种输出格式**:支持Markdown、结构化数据、截图、HTML、链接、元数据等多种格式。
- • **处理复杂内容**:能够处理代理、反机器人机制、动态内容(JS渲染)、输出解析等问题。
- • **高度可定制**:支持排除特定标签、自定义请求头、设置最大爬取深度等。
- • **媒体解析**:支持解析PDF、DOCX、图片等媒体文件。
- • **可靠性**:设计宗旨是获取你需要的数据,无论难度多大。
- • **页面交互**:支持在抓取前对页面进行点击、滚动、输入、等待等操作。
- • **批量处理**:支持同时抓取数千个URL。
-
- 
## 使用方式
- • **API调用**:通过RESTful API进行调用,支持多种编程语言的SDK,包括Python、Node.js、Go、Rust等。
- • **SDK**:Python、Node、Go、Rust
- • **LLM 框架**:Langchain (python)、Langchain (js)、Llama Index、Crew.ai、Composio、PraisonAI、Superinterface、Vectorize
- • **低代码框架**:Dify、Langflow、Flowise AI、Cargo、Pipedream
- • **其他**:Zapier、Pabbly Connect
## 总结
Firecrawl 是一个功能强大、高度灵活的网站数据提取工具,适用于需要将网站内容转化为LLM就绪数据的各种应用场景,如AI应用开发、数据分析、内容整合等。无论是小型项目还是大型企业应用,它都能提供高效、可靠的解决方案。
项目地址:
**https://www.firecrawl.dev/**
https://github.com/mendableai/firecrawl/

·················END·················
### **推荐阅读**
• [Github 资料项目合集](https://mp.weixin.qq.com/s?__biz=MzkyNDYyODg0MQ==&mid=2247488210&idx=1&sn=9b97cc6da4bdaf42ba779d4d0d66f5a1&scene=21#wechat_redirect)[](http://mp.weixin.qq.com/s?__biz=MzkyNDYyODg0MQ==&mid=2247485121&idx=1&sn=97093dfe7da78fb786bb999a284ee1fc&chksm=c1d3a4c7f6a42dd1df4cb4de4c057671d57274480eac57e61b4f6bae86aef03ff26bf23ffdd6&scene=21#wechat_redirect)• [4核 16G 就能 RAGFlow Quick start 快速入门](http://mp.weixin.qq.com/s?__biz=MzkyNDYyODg0MQ==&mid=2247485121&idx=1&sn=97093dfe7da78fb786bb999a284ee1fc&chksm=c1d3a4c7f6a42dd1df4cb4de4c057671d57274480eac57e61b4f6bae86aef03ff26bf23ffdd6&scene=21#wechat_redirect)• [ github 7.8k star 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。](https://mp.weixin.qq.com/s?__biz=MzkyNDYyODg0MQ==&mid=2247485065&idx=1&sn=8b71c116b61add064e0892da63a7bf6d&scene=21#wechat_redirect)